



I. Introduction▲
Avec l'avènement de l'informatique cognitive et des machines intelligentes, l'apprentissage automatique de ses algorithmes et des techniques connexes est très important. Nous pouvons utiliser l'apprentissage automatique pour nous aider à comprendre et extraire des informations utiles dans une abondance de données en constante évolution. L'apprentissage automatique peut être utilisé pour reconnaître et identifier des modèles complexes, pour générer des prédictions, pour apprendre au fil du temps, et finalement nous aider à mieux faire en prenant de meilleures décisions.
IBM fournit maintenant un certain nombre de services cognitifs sur Bluemix. Dans cet article, je présente le service Natural Language Classifier de Watson (classificateur du langage naturel). Il s'agit d'un classificateur d'apprentissage automatique qui combine les réseaux neuronaux complexes en convolution avec un modèle de langage sophistiqué pour apprendre et comprendre le langage. Malgré sa complexité interne, ce classificateur est très facile à utiliser.
Dans cet article, nous allons créer une application de classification de spams en créant une nouvelle instance du classificateur de Watson, ensuite l'entrainer à la distinction entre le spam et non-spam puis nous allons tester son exactitude.
II. De quoi aurez-vous besoin ?▲
Pour construire votre propre classificateur de spam qui utilise celui de Watson et Bluemix, vous aurez besoin de :
- un compte Bluemix ;
- un compte IBM DevOPS Services ;
- curl - un outil de ligne de commande pour transférer des données avec une syntaxe URL ;
- un interpréteur Python.
III. Entrainer le classificateur du langage naturel de Watson▲
Pour utiliser le service du classificateur de Watson pour trier le spam, nous avons besoin de l'entrainer. Pour ce faire, le classificateur utilise un ensemble connu d'observations étiquetées pour former un modèle capable de générer des prévisions raisonnables. Il s'agit d'un algorithme d'apprentissage supervisé.
Une observation étiquetée n'est rien de plus qu'un vecteur d'attributs avec une étiquette. Dans le cas du classificateur de Watson, chaque observation se compose d'un texte (au lieu d'un vecteur d'attributs) et une étiquette de classe, comme le montre le code ci-dessous :
Label Text
spam Join xyz.com NOW!!!! And WIN $1,000,000!!!!!!
ham Hi Mom. I hope dinner went well with Auntie Jane. Love you.Nous allons commencer !
IV. Étape 1 Créer un service de classificateur de langues naturelles de Watson▲
Notre première étape sera de créer une instance dans le classificateur de Watson, qui deviendra notre service Watson.
- Connectez-vous à votre compte Bluemix (ou inscrivez-vous pour un essai gratuit).
-
Allez dans le catalogue Bluemix, effectuez une recherche et sélectionnez le classificateur de langues naturelles de Watson.

-
À droite, sous la section Add Service, assurez-vous que Leave unbound est sélectionné, donnez un nom pour votre service (par exemple, spam_classifier), et cliquez sur CRÉER.
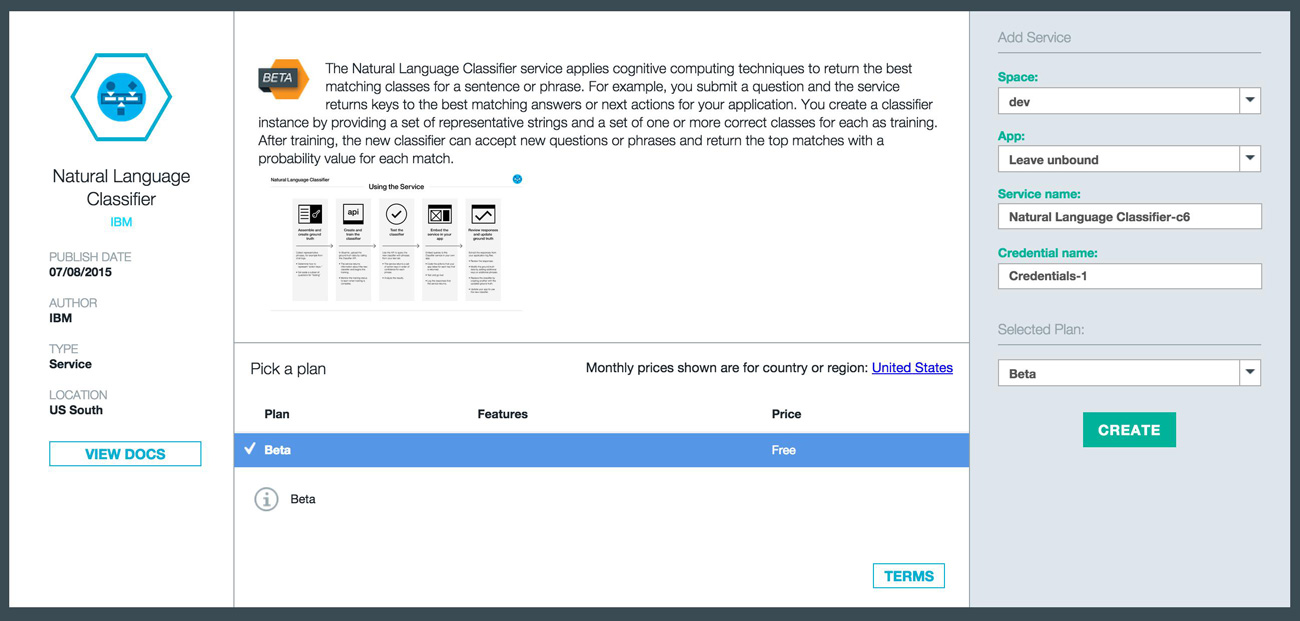
-
Revenez sur le tableau de bord Bluemix, défilez-le jusqu'à vos services et cliquez sur la nouvelle instance de service que vous venez de créer.

- Sélectionnez Service Credentials pour voir l'URL et les informations d'identification du service du classificateur de Watson:

Prenez note de ces identifiants, ils seront utiles plus tard dans ce tutoriel
V. Étape 2 Configurer votre environnement de développement ▲
Pour la suite, vous aurez besoin de réunir quelques fichiers du dépôt du projet de WatsonNLCSpam.
-
Cloner le dépôt Git WatsonNLCSpam.
-
Dans votre terminal, entrez la commande suivante :
Sélectionnezgit clone https://hub.jazz.net/git/dimascio/WatsonNLCSpam -
Lorsque vous êtes invité, entrez votre identifiant IBM.
-
-
Passez en revue le contenu du dépôt.
- README.md décrit le projet.
- data contient l'ensemble des données d'entrainement (SpamHam-Train.csv) et de données de test (SpamHam-Test.json) pour le classificateur de spams.
- spam.py est le script qui est utilisé pour faire des tests de prévisions basiques.
- web contient le code source pour l'application web qui va servir d'exemple.
V-A. À propos des données d'entrainement▲
Les données d'entrainement pour le classificateur de spams sont contenues dans le fichier SpamHam-Train.csv. Il contient 90 % de l'ensemble des données d'origine. Les 10 % restant sont mis de côté pour l'ensemble des tests. Le contenu du SpamHam-Train.csv est formaté en CSV et stocké dans une structure qui est compatible avec le classificateur de langues naturelles de Watson. Chaque ligne contient un text et un label.
Passer en revue les exemples de données suivantes qui proviennent du fichier SpamHam-Train.csv :
"=Bring home some Wendy =D",ham
"100 dating service cal;l 09064012103 box334sk38ch",spam
"Whatsup there. Dont u want to sleep",ham
"""Are you comingdown later?""",ham
"Alright i have a new goal now",hamCette classification est assez simple grâce à deux caractéristiques :
- Il est un classificateur binaire et il se présente en deux classes : spam et ham.
- Chaque observation est associée à une seule classe : "Alright i have a new goal now",ham
Le classificateur de langage naturel de Watson est capable de faire des observations et une classification multiclasse, mais je n'utilise pas ces capacités dans ce tutoriel.
V-B. À propos des métadonnées d'entrainement▲
Une métadonnée d'entrainement est une donnée qui décrit une donnée d'entrainement. Elle indique le langage visé (dans ce cas, il s'agit de en pour dire que le langage utilisé est l'anglais) et le nom du classificateur (SpamHam dans notre cas). La métadonnée formée doit être formatée sous JSON. Un exemple ci-dessous :
{
"language":"en",
"name":"Spam Ham"V-C. À propos des données de test▲
Après qu'un classificateur est entrainé, il est important de tester son exactitude. SpamHam-Test.json est le fichier qui contient les données de test. Comme les données d'entrainement , les données de test constituent un ensemble d'observations libellées. Dans notre, il s'agit de “I love you mom!”,ham. Les observations de test ne sont pas incluses dans l'ensemble des données d'entrainement et peuvent donc être utilisées pour évaluer l'exactitude de notre classificateur.
Il est considéré comme une mauvaise pratique de réutiliser les observations faites au cours d'un entrainement pour tester la précision d'un classificateur. Parce que ces observations sont « visibles » pendant l'entrainement et les réutiliser lors des tests va probablement conduire à un résultat ayant une précision trop optimiste.
Le classificateur de langage naturel Watson est un exemple parfait. Si toutes les observations de test sont visibles pendant la formation, dans ce cas l'exactitude du classificateur de langage naturel de Watson est à cent pour cent. Cependant, nous sommes finalement intéressés par la précision de la classification malgré des observations pas encore vues jusque là. Ce test va nous donner une meilleure idée de la façon dont le classificateur généralisera les observations d'entrainement à de nouvelles observations.
Les données de test fournies, SpamHam-Test.json, sont structurées différemment à partir des données d'entrainement fournies dans le fichier SpamHam-Train.csv. Chaque ligne dans le fichier contenant les données de test est un objet JSON qui représente une seule observation libellée. Les données de test peuvent tout aussi facilement être mises au format CSV. Plus tard dans ce tutoriel, je vais vous montrer comment utiliser ces données de test au format JSON avec spam.py pour calculer la précision de la classification de spam.
VI. Étape 3 Créer et former le classificateur de spam▲
Lors de la première étape, nous avons cloné une instance du classificateur de langage naturel de Watson pour créer notre service du classificateur de langage naturel Watson. Maintenant, nous allons utiliser ce service pour créer un classificateur de spam.
Créer le classificateur est facile. Tout ce que nous avons besoin de faire, c'est de faire un POST à la fin du /v1/classifiers en utilisant la commande curl ci-dessous :
curl -X POST -u username:password -F training_data=@SpamHam-Train.csv -F training_metadata="{\"language\":\"en\",\"name\":\"My Classifier\"}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers"Cette commande curl requiert <un nom d'utilisateur>, <un mot de passe>, et un <URL>. Ces variables doivent être remplacées par les valeurs appropriées des informations d'identification qui ont été fournies à l'étape 1.
Après avoir exécuté cette commande, prenez note de son classifier_id. Nous allons l'utiliser prochainement. Entrainer le classificateur peut prendre jusqu'à 30 minutes, il s'agit donc d'un bon moment pour faire une pause.
VII. Étape 4 Vérifier l'état d'avancement de la formation▲
Pour savoir si le classificateur est prêt à l'emploi, nous pouvons invoquer le classificateur de langage naturel de Watson en utilisant la requête GET ci-dessous :
curl -u <username>:<password> <url>/v1/classifiers/<classifier-id>Quand le classificateur indique que c'est prêt à l'emploi, allez à l'étape suivante.
VIII. Étape 5 Essayer le classificateur de spam▲
Maintenant que nous avons entrainé le service antispam du classificateur, nous pouvons faire des essais.
Comme un exercice rapide, faites la requête POST au critère /classify :
curl -X POST -u <username>:<password> -H "Content-Type:application/json" -d "{\"text\":\"I love you mom\"}" <uri>/v1/classifiers/<classifier_id>/classifyAlternativement, vous pouvez faire une requête GET :
curl -G -u <user>:<password> <uri>/v1/classifiers/6C76AF-nlc-43/classify" --data-urlencode "text=what is your phone number?"L'identifiant classifier_id est retourné par l'appel du /v1/classifiers qu'on a conçu plus tôt. Si vous avez oublié l'identification en invoquant les critères suivants avec l'option de commande curl. Ce critère vous donnera une liste qui contient tous vos classificateurs.
curl -u <username>:<password> <uri>/v1/classifiers"IX. Étape 6 Tester la précision de la classification▲
Enfin, pour tester notre classificateur et calculer sa précision, nous allons utiliser le script Python spam.py. Ce script invoque la même requête POST qui est décrite dans l'étape précédente, ensuite il compte le nombre de prédictions classifiées qui correspondent correctement au libellé. La précision est calculée en prenant le nombre de prédictions correctes et en divisant par le nombre total d'observations de test.
Lançons le script.
- Ouvrez spam.py et mettez à jour YOUR_CLASSIFIER_ID, YOUR_CLASSIFIER_USERNAME, et YOUR_CLASSIFIER_PASSWORD pour les référencer à vos identifiants du service de votre classificateur de langage naturel de Watson, qui se trouve à l'étape 1.
- Dans le répertoire de projet, exécutez la commande suivante :
python spam.pyLorsque le script est terminé, vous devriez voir la sortie suivante :
accuracy: 0.993079584775X. Conclusion ▲
Le classificateur de langage naturel de Watson apporte un apprentissage automatique sophistiqué à Bluemix. L'interface REST, accessible et intuitive, permet aux développeurs de tout horizon à rapidement entrainer, tester et appliquer de nouveaux classificateurs aux problèmes du monde réel. Dans cet article, vous avez appris comment utiliser le classificateur de langage naturel de Watson pour concevoir, entrainer et tester un classificateur de spam. Nous attendons maintenant de voir ce que vous pouvez faire avec ce classificateur.